จงทำการศึกษาค้นคว้า Types of Search Engines แต่ละประเภทดังนี้ พร้อมยกตัวอย่างประกอบของแต่ละประเภทให้ชัดเจน

Crawler-Based Search Engines
Crawler Based Search Engines คือ เครื่องมือการค้นหาบนอินเตอร์เน็ตแบบอาศัยการบันทึกข้อมูลและจัดเก็บข้อมูลเป็นหลัก ซึ่งจะเป็นจำพวก Search Engine ที่ได้รับความนิยมสูงสุด เนื่องจากให้ผลการค้นหาแม่นยำที่สุดและการประมวลผลการค้นหาสามารถทำได้อย่างรวดเร็วจึงทำให้มีบทบาทในการค้นหาข้อมูลมากที่สุดในปัจจุบัน
โดยมีองประกอบหลักเพียง 2 ส่วนด้วยกัน คือ
1. ฐานข้อมูล โดยส่วนใหญ่แล้ว Crawler Based Search Engine เหล่านี้จะมีฐานข้อมูลเป็นของตัวเองที่มีระบบการประมวลผลและการจัดอันดับที่เฉพาะเป็นเอกลักษณ์ของตนเองอย่างมาก
2. ซอฟแวร์ คือ เครื่องมือหลักสำคัญที่สุดอีกส่วนหนึ่งสำหรับ Search Engine ประเภทนี้ เนื่องจากต้องอาศัยโปรแกรมเล็ก ๆ ทำหน้าที่ในการตรวจหาและทำการจัดเก็บข้อมูลหน้าเพจหรือเว็บไซต์ต่างๆในรูปแบบของการทำสำเนาข้อมูลเหมือนกับต้นฉบับทุกอย่าง ซึ่งเราจะรู้จักกันในนาม Spider หรือ Web Crawler หรือ Search Engine Robots
ตัวอย่าง หนึ่งของ Crawler Based Search Engine ชื่อดัง http://www.google.com Crawler Based Search Engine ได้แก่ Google , Yahoo, MSN, Live, Search, Technorati (สำหรับ blog) ส่วนลักษณะการทำงานและการเก็บข้อมูลของ Web Crawler หรือ Robot หรือ Spider นั้นแต่ละแห่งจะมีวิธีการเก็บข้อมูลและการจัดอันดับข้อมูลที่ต่างกัน
YAHOO
MSN

LIVE
Technorati (สำหรับ blog)
อ้างอิง
Directories
Web Directory หรือ Blog Directory คือ สารบัญเว็บไซต์ที่ให้คุณสามารถค้นหาข่าวสารข้อมูลด้วยหมวดหมู่ข่าวสารข้อมูลที่เกี่ยวข้องกันในปริมาณมากๆคล้ายๆกับสมุดหน้าเหลืองซึ่งจะมีการสร้างดรรชนี มีการระบุหมวดหมู่อย่างชัดเจนซึ่งจะช่วยให้การค้นหาข้อมูลต่างๆตามหมวดหมู่นั้นๆ ได้รับการเปรียบเทียบอ้างอิงเพื่อหาข้อเท็จจริงได้ในขณะที่เราค้นหาข้อมูลเพราะว่าจะมีเว็บไซต์มากมาย หรือ Blog มากมายที่มีเนื้อหาคล้ายๆ กันในหมวดหมู่เดียวกันให้เราเลือกที่จะหาข้อมูลได้อย่างตรงประเด็นที่สุด (ลดระยะเวลาได้มากในการค้นหา)
ตัวอย่าง
ODP Web Directory ชื่อดังของโลก ที่มี Search Engine มากมายใช้เป็นฐานข้อมูล Directory

http://www.dmoz.org
1.ODP หรือ Dmoz ที่หลายๆ คนรู้จัก ซึ่งเป็น Web Directory ที่ใหญ่ที่สุดในโลก Search Engine หลาย ๆ แห่งก็ใช้ข้อมูลจากที่แห่งนี้เกือบทั้งสิ้น เช่น Google, AOL, Yahoo, Netscape และอื่น ๆ อีกมากมาย ODP มีการบันทึกข้อมูลประมาณ 80 ภาษาทั่วโลกรวมถึงภาษาไทยด้วย

http://webindex.sanook.com
2. สารบัญเว็บไทย SANOOK ก็เป็น Web Directory ที่มีชื่อเสียงอีกเช่นกันและเป็นที่รู้จักมากที่สุดในเมืองไทย
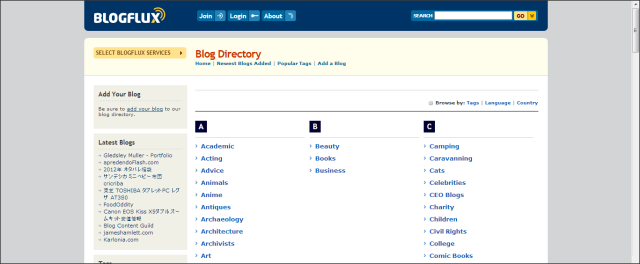
3. Blog Directory อย่าง BlogFlux Directory ที่มีการเก็บข้อมูลเกี่ยวกับบล็อกมากมายตามหมวดหมู่ต่างๆ หรือ Blog Directory อื่น ๆ ที่สามารถหาได้จาก Make Many แห่งนี้
อ้างอิง
Hybrid Search Engines
Hybrid Search Engines เสิร์ชเอนจิ้นลูกผสมทุกวันนี้มีพัฒนาการของเสิร์ชเอนจิ้นในลักษณะที่นำข้อดีของทั้ง crawler-based และ directories มาใช้งานมากขึ้นแต่โดยปกติแล้วเสิร์ชเอนจิ้นลูกผสมนั้นมักจะให้ผลลัพธ์ในการค้นหาเอียงไปทางใดทางหนึ่งมากกว่าอีกทางหนึ่ง เช่น MSN search นั้น มักจะโอนเอียงไปทางไดเรกทอรี่ที่ดูแลโดย editor มากกว่า crawler-based อาทิเช่น LookSmart (เสิร์ชเอนจิ้นตัวหนึ่งของ MSN) แต่ก็มีการโอนเอียงไปทาง crawler-based เช่นกัน อาทิเช่น Inktormi (เสิร์ชเอนจิ้นตัวหนึ่งของ MSN)โดยเฉพาะอย่างยิ่งคำค้นหาที่มีความสลับซับซ้อนมากๆ
ตัวอย่าง
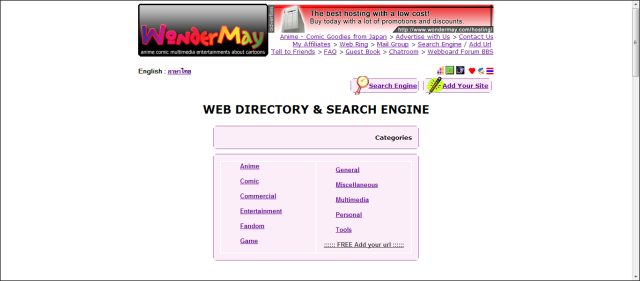
http://www.wondermay.com/search/index.htm
อ้างอิง
Meta Search Engines
Meta Search Engine คือ Search Engine ที่ใช้หลักการในการค้นหาโดยอาศัย Meta Tag ในภาษา HTML ซึ่งมีการประกาศชุดคำสั่งต่างๆ เป็นรูปแบบของ Tex Editor ด้วยภาษา HTML นั่นเอง เช่น ชื่อผู้พัฒนา คำค้นหา เจ้าของเว็บ หรือ บล็อก คำอธิบายเว็บหรือบล็อกอย่างย่อผลการค้นหาของ Meta Search Engine นี้มักไม่แม่นยำอย่างที่คิด เนื่องจากบางครั้งผู้ให้บริการหรือผู้ออกแบบเว็บสามารถใส่อะไรเข้าไปก็ได้มากมายเพื่อให้เกิดการค้นหาและพบเว็บหรือบล็อกของตนเองและอีกประการหนึ่งก็ คือ มีการอาศัย Search Engine Index Server หลายๆ แห่งมากประมวลผลรวมกันจึงทำให้ผลการค้นหาข้อมูลต่าง ๆ ไม่เที่ยงตรงเท่าที่ควร
Search Engines ประเภทนี้อาจจัดได้ว่าไม่ใช่ Search Engines ที่แท้จริงเนื่องจากไม่ได้ทำการสืบค้นข้อมูลเองแต่จะส่งต่อคำถามจากผู้ใช้ (query) ไปให้ Search Engines ตัวอื่นผลการค้นที่ได้จึงแสดงที่มา (ชื่อของ Search Engines) ที่เป็นเจ้าของข้อมูลไว้ต่อท้ายรายการที่ค้นได้แต่ละรายการ
ข้อดีของ Search Engines ประเภทนี้คือ
สามารถค้นเรื่องที่ต้องการได้จากแหล่งเดียวไม่ต้องเสียเวลาไปค้นจากหลายที่โดย Search Engines จะตัดข้อมูลที่มีความซ้ำซ้อนกันออกไปเหมาะที่จะใช้ในกรณีที่ต้องการรวบรวมข้อมูลที่ต้องการให้ครอบคลุมมากที่สุดเนื่องจาก Search Engines เพียงตัวเดียวอาจรวบรวมข้อมูลได้ไม่ครอบคลุมทั้งหมด หรือ Search Engines อาจไม่ได้ทำดรรชนีให้และที่สำคัญช่วยประหยัดเวลาในการค้นให้กับผู้ใช้
ข้อด้อยที่ต้องคำนึงถึง
คำค้นที่ Search Engines แต่ละตัวใช้มีโครงสร้างประโยค (Syntax) ของตนเองซึ่งแตกต่างกันไปแต่ผู้ใช้จะใส่คำค้นที่ Multi Search Engines เพียงคำค้นเดียว (Query) ในกรณีที่คำค้นมีการสร้างสูตรการค้นที่ซับซ้อนหรือใช้ภาษาอื่นๆ ที่ไม่ใช่ภาษาอังกฤษอาจให้ผลการค้นไม่เที่ยงตรงได้เนื่องจากไม่เข้าใจคำสั่งที่แท้จริง
ตัวอย่าง Meta Search Engines
-
Dogpile (http://www.dogpile.com)

-
Metacrawler (http://www.metacrawler.com)

-
ProFusion (http://www.profusion.com)
-
Search (http://www.search.com)
-
SurfWax (http://www.surfwax.com)
-
Ixquick (http://www.ixquick.com)
-
www.thaifind.com

อ้างอิง
-
http://blog.seo.co.th/%E0%B8%9B%E0%B8%A3%E0%B8%B0%E0%B9%80%E0%B8%A0%E0%B8%97%E0%B8%82%E0%B8%AD%E0%B8%87-search-engine
-
http://home.kku.ac.th/hslib/412141/internet/metasearch.htm
Specialty Search Engines
เป็นซอฟต์แวร์หรือบริการที่ให้บริการค้นหาข้อมูลเฉพาะประเภทที่อยู่ในสภาวะจำกัดเท่านั้น เช่น http://www.amazon.com จะมีเครื่องมือสืบค้นหาหนังสือหรือสินค้าที่สามารถค้นหาได้เฉพาะในร้านของตนเองเท่านั้น napster เป็นซอฟต์แวร์ที่ให้บริการค้นหาเพลงเฉพาะผู้ที่สมัครเป็นสมาชิกเท่านั้น http://www.dejanews.com เป็นบริการค้นหาสารสนเทศจาก Newsgroups เท่านั้น
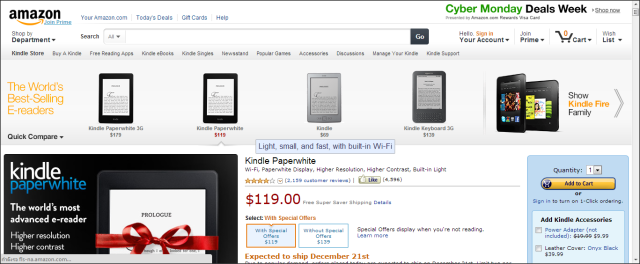
www.amazon.com

